NCC Switch - v3.16.1
Manage seven AI programming assistants like Claude Code, Codex, and Gemini CLI from a single interface

Open source local deployment tool for large language models (LLMs)
0 Already downloaded Mobile view
Ollama is an open-source tool for local deployment of large language models (LLMs). It allows you to easily run Llama 3.3, DeepSeek-R1, Phi-4, Mistral, Gemma 2 and other large models locally on your computer, free from network restrictions, censorship, and providing greater privacy and security. You can ask it anything.
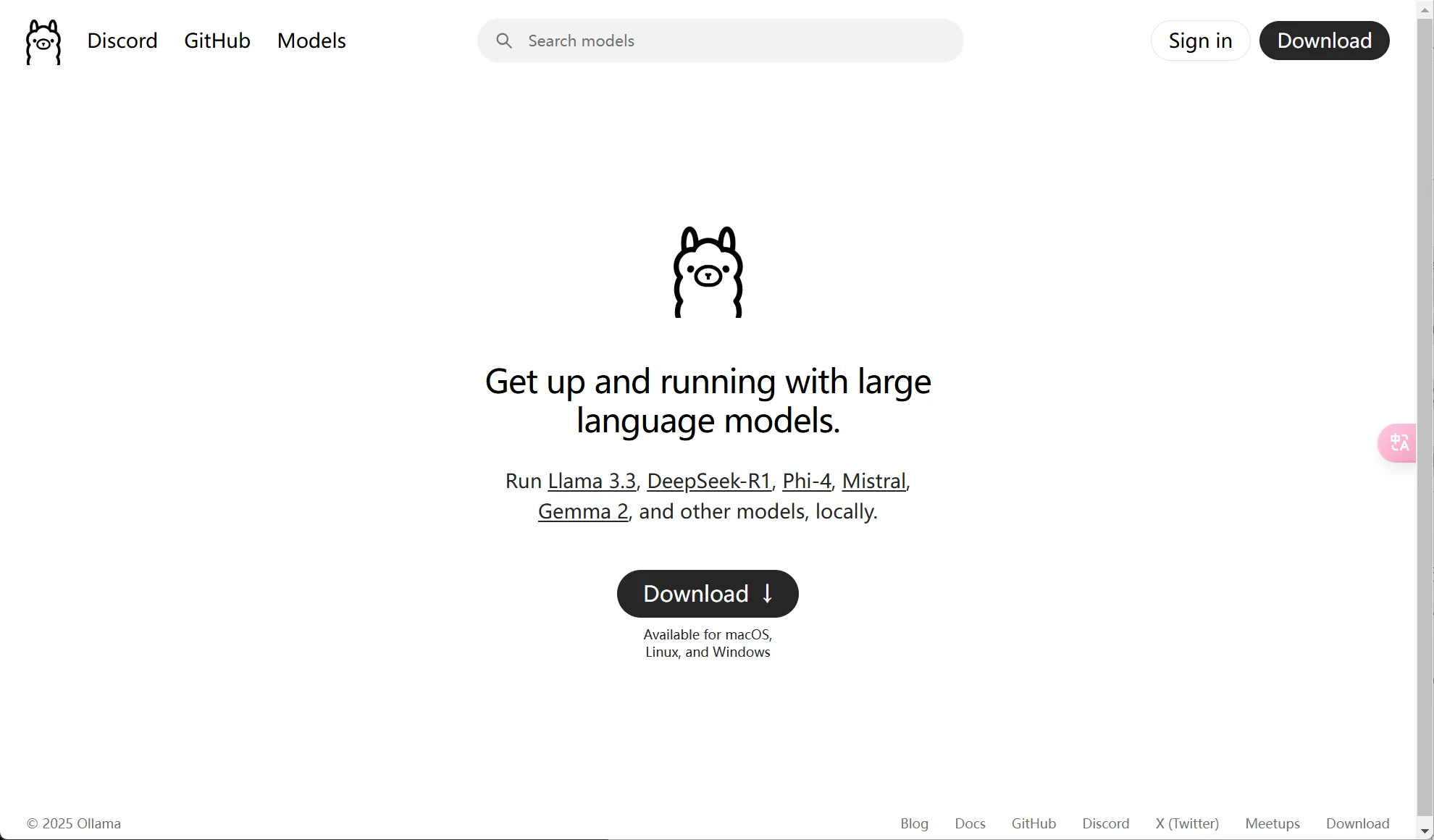
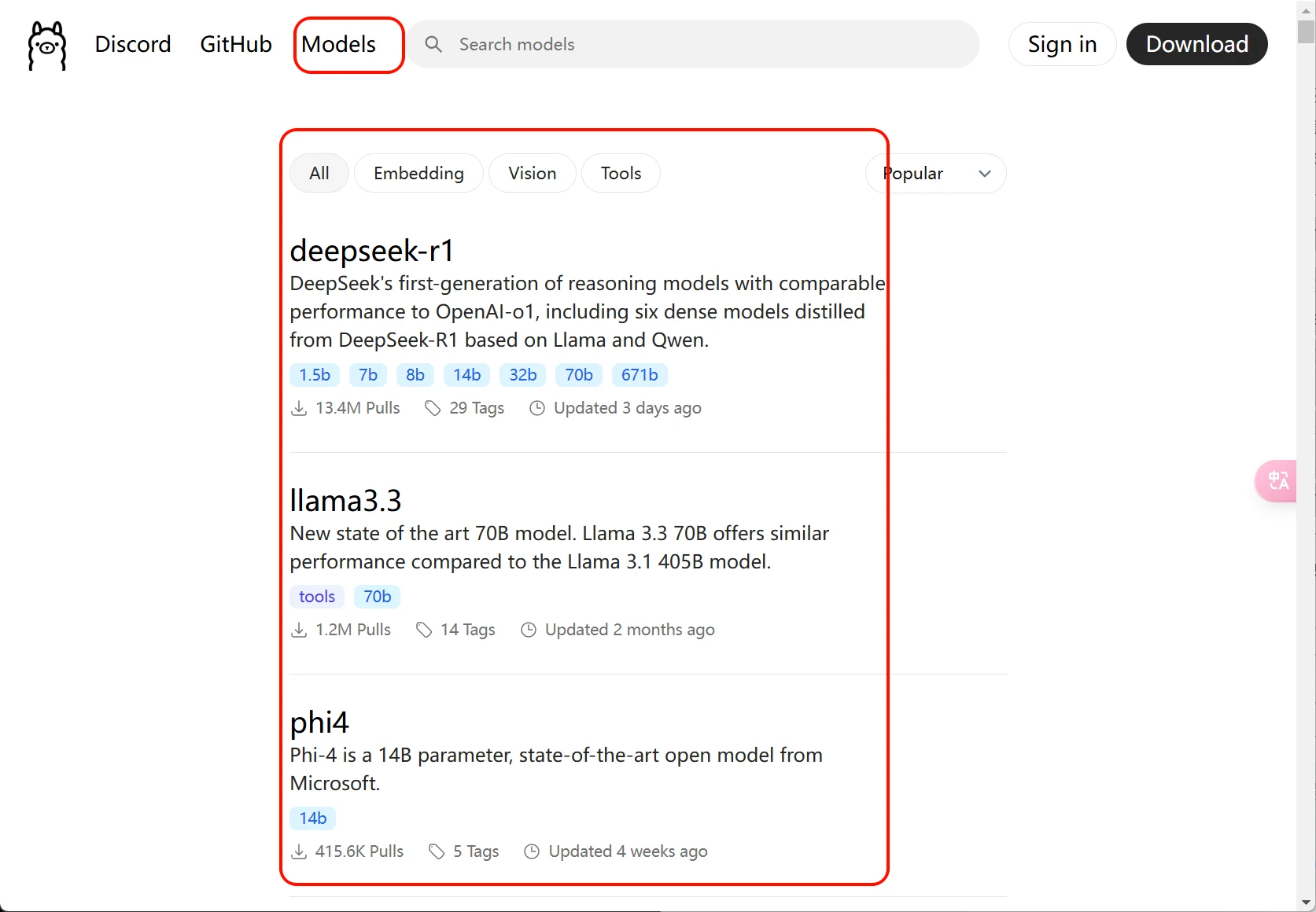
Built-in rich collection of open-source models, including text generation, code writing, multimodal reasoning, etc., such as the Llama series, Gemma 2, DeepSeek-R1, Phi-4, Mistral, and more.
Supports importing models from GGUF, PyTorch, Safetensors and other formats, and customizing parameters via Modelfile. It can run image reasoning models (like LLaVA) and code generation models (like Codestral), supports joint text and image processing, and provides REST API and Python/JavaScript SDK for easy integration into applications or workflows.
Lightweight and efficient, supports CPU/GPU hybrid inference. 8GB of video memory is sufficient to run a 7B parameter model smoothly.
I wrote a tutorial on deploying the DeepSeek-R1 large model with Ollama on my Tuding AI Navigation. Interested friends can check it out!!